8 min to read
Service Monitoring / TIL
Service Monitoring

Service Monitoring
CI/CD의 마지막 파이프라인인 Stage는 운영은 서비스에 생길 수 있는 현황을 파악하고 문제를 모니터링하는 과정으로 대표된다. 그렇다면 모니터링은 어떤 지표를 수집하고, 어떤 *메트릭을 기준으로 삼아야 할까?
모니터링의 목표
- 시간을 기준으로 측정되는 주요 메트릭을 최소화하여 고가용성을 달성
- 사용량을 추적하여, 배포에 앞서 세운 가설을 검증하고 개선 (애자일에서는 ‘검증된 학습(Validated learning)을 적용한다’라고 한다.)
구글의 모니터링의 목표
- 장기적인 트렌드 분석
- DB가 얼마만큼 용량을 차지하며, 얼마나 빨리 용량이 증가하는가?
- DAU(일간 활성 사용자수)는 얼마나 빨리 증가하는가?
- 시간의 경과 및 실험 그룹 간의 비교
- 어떤 DB를 썼을 때 쿼리가 빠른가?
- 캐시용 노드를 추가했을 때, 캐시 적중률이 얼마나 향상되는가?
- 지난주보다 사이트가 얼마나 느려졌는가?
- 경고
- 인프라의 어떤 부분이 고장 났는가? 혹은 고장날 수 있는가?
모니터링의 종류
| ’-‘ | 블랙 박스 모니터링 | 화이트 박스 모니터링 |
|---|---|---|
| 관찰자 시점 | 밖에서 바라봄 | 안에서 바라봄 |
| 특징 | 인프라 수준, 쿠버네티스 컴포넌트 자체를 모니터링 | 측정 기준에 따른 모니터링 |
| ’-‘ | 애플리케이션이 왜 오류를 내는 지 알 수 없음 | 현상이 발생한 근거를 알 수 있는 모니터링 방식 |
| 예 | CPU/메모리/스토리 등 | HTTP 요청, 500 에러의 발생 횟수, 레이턴시 등 |
어떠한 서비스가 제대로 작동되는 지 확인하려면, 서비스 또는 시스템과 관련한 모든 변수들을 모니터링해야 한다. 모니터링을 할 때에는 단계를 구분해서 계층적으로 할 필요가 있다.
논리적인 리소스의 집합이 하나의 상위 계층을 만든다. 컨테이너 오케스트레이션 툴이나, AWS의 서비스가 제공하는 계층을 이해하면, 어떤 것을 모니터링해야 하는지 보다 쉽게 파악이 가능하다. 파드나, 컨테이너 안에 포함된 애플리케이션의 메트릭은 별도로 다룬다.
계층에 따른 모니터링 구분
- 쿠버네티스 : 노드 > 클러스터 컴포넌트 > 파드
- ECS : 클러스터 > 서비스 > 태스크
- EC2 : 인스턴스에 대한 메트릭만 볼 수 있다.
- Lambda : 함수에 대한 메트릭만 볼 수 있다.
메트릭
시간에 따라 측정한 결과값으로, 비즈니스 개념을 나타내는 수치 측정을 의미하기도 한다.
예를 들어, 시간당 CPU 사용률, 연간 순매출과 같이 시간이라는 차원이 함께 적용되어야 한다. 시간이 아닌 다른 차원(서비스 별 매출)을 기준으로 삼을 수도 있다.
- 주요 메트릭은, 단일 노드일 경우 리눅스를 통해 측정할 수 있다.
- 클러스터 형태, 즉 여러 대의 노드로 구성되어 있는 경우, AWS 콘솔(CloudWatch 등)을 통해 이미 제공되고 있는 경우가 많다.
MS(Azure 서비스)에서 보는 메트릭
- 캐시 사용률
- CPU, Memory
- 인스턴스의 개수
- 연결 유지
Proxy 서버의 메트릭
애플리케이션 서버(AWS)의 앞단에 캐시 서버 혹은 인증 서버, 로드 밸런서와 같은 Proxy 서버가 존재한다면, 이는 애플리케이션 서버와는 별도로 모니터링해야 한다. 애플리케이션 서버가 각 노드의 컴퓨팅 자원을 모니터링 하는 데에 중점을 두었다면, Proxy 서버, 그 중에서도 HTTP 라우팅을 다루고 있는 서버는 요청 그 자체와 연관된 메트릭을 위주로 모니터링해야 한다.
HTTP 요청/응답 관련 모니터링 대상은 쿠버네티스의 경우 인그레스, AWS 생태계에서는 Application Load Balancer를 중점으로 보아야 한다.
메트릭 한눈에 보기
| ’-‘ | 컴퓨팅 유닛 관련 메트릭 | 요청/응답 관련 메트릭 | 스케일링 관련 메트릭 |
|---|---|---|---|
| k8s | CPU 사용량 (utilization), 메모리 사용량, 네트워크 in/out, 디스크 사용량 (노드 및 파드 별) | etcd latency, ingress, 요청 개수, 요청 latency, 에러율 | 디플로이먼트 상황 |
| ECS | CPU 사용량, 메모리 사용량, 네트워크 in/out (클러스터 및 서비스 별) | 해당 사항 없음 (ALB와 사용하여 분석해야 함) | 서비스 개수, (원하는/실행 중인/보류 중인) 작업 개수, 컨테이너 인스턴스 개수 |
| EC2 | CPU 사용량, 네트워크 in/out, 네트워크 패킷 in/out, 디스크 읽기/쓰기 (바이트), 작업 개수, CPU 크레딧 사용량, 밸런스 | 상태 검사 실패 횟수 | 해당 사항 없음 |
| Lambda | 해당 사항 없음 | 호출 개수, 실행 시간, 에러 개수 및 성공률, throttles, async delivery failures, IteratorAge | 동시 실행 횟수 |
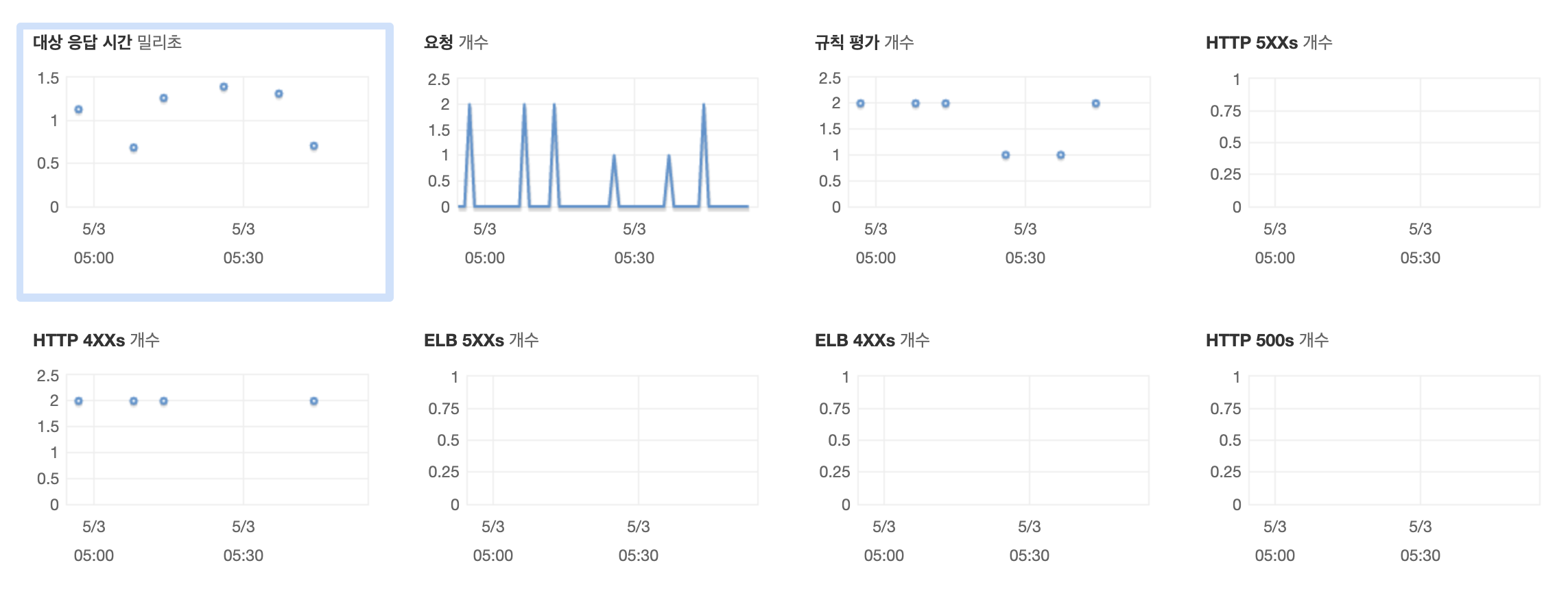
| ALB | 해당 사항 없음 | 대상 응답 시간, 요청 개수, 응답 코드 개수 (2xx, 4xx, 5xx), 대상 연결 오류, 거부된 연결 개수 합계, 대상 TLS 협상 오류, 클라이언트 TLS 협상 오류, 활성 연결 개수, 새 연결 개수, 처리된 바이트, 사용된 Load Balancer 용량 단위 | 해당 사항 없음 |
Application Load Balancer
ECS
- 클러스터

- 서비스
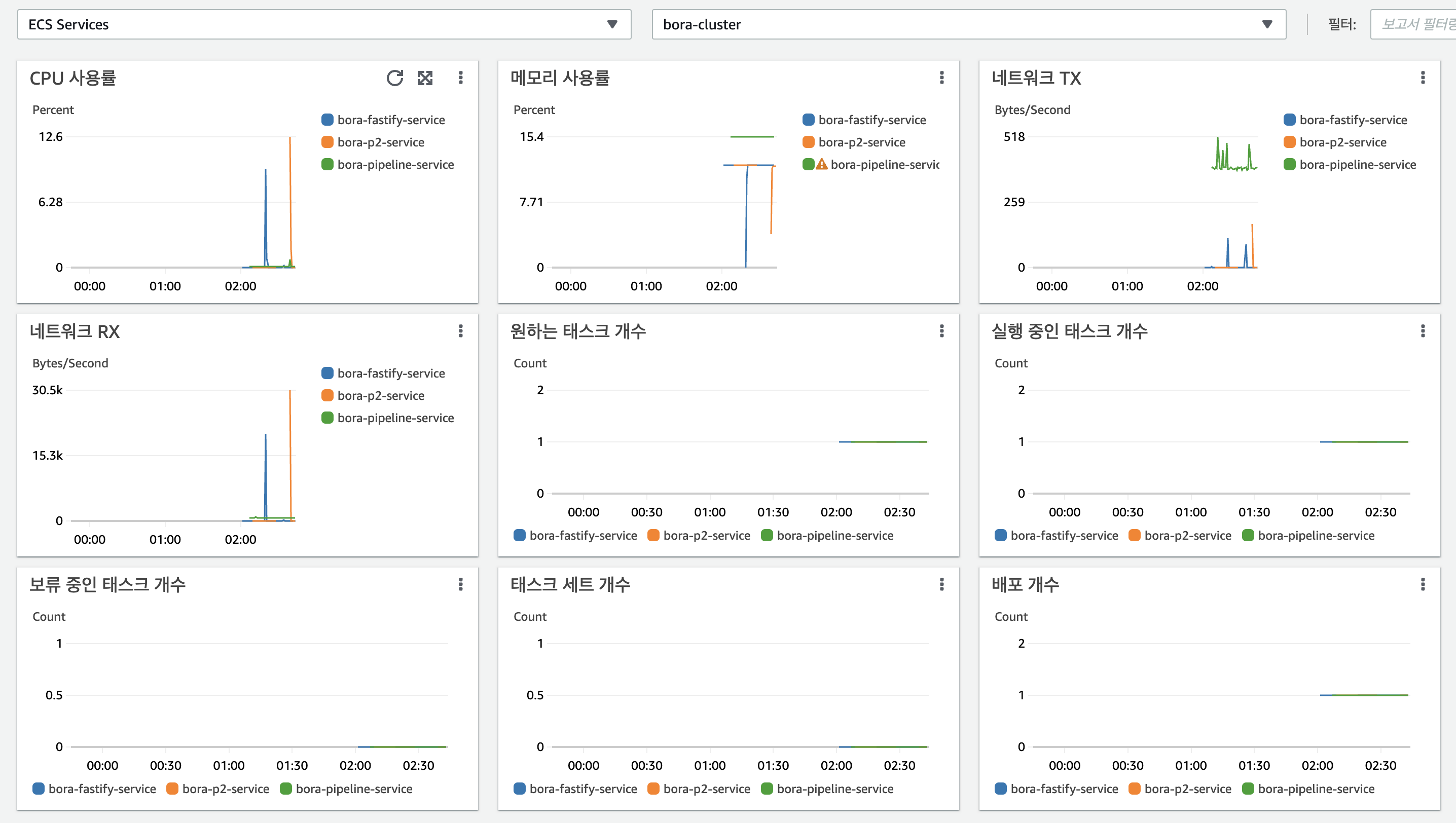
- 태스크

EC2

Lambda

사이트 신뢰성 엔지니어링 (SRE) 메트릭
CPU 및 메모리, 사용량 등을 파악하는 것 외에도 네트워크 요청에 따른 응답 상태, 요청의 횟수나 시간 등도 중요한 지표가 될 수 있는데, 이를 통해 어떤 서비스가 온전히 사용자에게 전달될 수 있도록 가용성을 극대화하는 기술/문화를 특별히 “사이트 신뢰성 엔지니어링(SRE)”라고 부른다.
구글의 SRE 조직에서 정의한 SRE 모니터링 주요 측정 항목 : “The Four Golden Signals”
-
대기 시간 (Latency)
서비스가 요청에 응답하는 데 걸리는 시간. 핵심은 지속 시간뿐만 아니라 성공적인 요청의 대기 시간과, 실패한 요청의 대기 시간을 구별하는 것이 중요하다. -
트래픽 (Traffic)
서비스에 대한 수요 측정. (초당 HTTP 요청 수) -
오류 (Errors)
실패한 요청/전체 요청의 비율로 측정된다. 대부분 이러한 실패는 명시적이지만(예: HTTP 500) 암시적일 수도 있다(예: HTTP 200, 본문에 결과 없음 응답) -
포화 수준(Saturation)
포화는 서비스 또는 시스템 리소스를 얼마나 가득 채워서 사용하는가로 설명할 수 있다.
ex > 과도한 CPU 자원 사용 - CPU 자원이 부족하면, 스로틀링을 초래하고 결과적으로 응용 프로그램의 성능을 저하시킨다.
대표적 모니터링 방법
- USE 패턴 : 모든 리소스에 대한 사용률(Utilization), 포화도(Saturation), 오류(Erroes)를 체크하는 패턴을 의미한다.
- RED 패턴 : 비율(Rate), 오류(Errors) 및 기간(Duration)을 주요 메트릭으로 정의하는 패턴이다.
Q1. 람다를 모니터링하려는 경우, 메트릭을 활용해 어떤 질문이 나올 수 있을까요? 레퍼런스(Lambda 키 메트릭)를 읽고, 어떤 질문을 해결할 수 있는지 알아봅시다.
Q1. 람다 함수의 실행 시간이 적절한가요?
네트워크 지연 시간은 실행 시간에 영향을 줄 수 있다. 코드 실행 속도가 느리면 콜드 스타트 또는 코드 복잡성이 원인일 수 있다.
Q2. 람다 함수에서 발생한 데드레터 오류가 있는지 확인할 수 있나요?
데드레터 오류 메트릭은 람다가 데드레터 대기열로 이벤트를 전송하지 못한 횟수를 추적한다. 이 메트릭이 증가하면 기능의 사용 권한에 문제가 있거나 다운스트림 서비스가 제한될 수 있다.
Q3. 람다 함수의 동시성이 적절하게 관리되고 있나요?
동시성 모니터링은 과도하게 프로비저닝된 기능을 관리하고 응용 프로그램 트래픽 흐름을 지원하는 데 도움이 된다. 함수가 처리할 수 있는 것보다 많은 요청이 있고 기능에 필요한 용량이 충분하지 않으면 지속적인 조절이 필요할 수 있다. 스로틀을 모니터링하면 기능에 대한 동시성 한계에 도달했는지 여부를 확인할 수 있다.
Q4. 람다 함수의 메모리 사용량이 적절한가요?
메모리 사용량을 모니터링하여 실행 시간과 비용 사이의 균형을 조정할 수 있다. 메모리가 부족하면 실행 시간이 느려질 수 있고, 반대로 필요 이상으로 메모리를 할당한 경우 비용이 증가할 수 있다.
Q5. 람다 함수의 실행 기간 및 청구 기간은 어떻게 모니터링할 수 있나요?
실행 시간을 추적하면 비용을 관리하고 최적화할 수 있는 기능을 판단할 수 있다. 실행 시간이 일정 임계값에 도달하는 시점을 확인하는 데 도움이 된다.
Q2. 쿠버네티스에 어떤 파드가 Pending 상태에 머물러있다면, 어떤 계층부터 살펴보아야 할까요? 이 경우는 파드가 Running 상태인데 잘 작동하지 않는 경우랑은 어떻게 다른가요? (서비스는 연결되어 있다고 가정합니다)
살펴보아야 하는 계층
- Node : 파드가 스케줄링되기 위해서는 실행할 수 있는 유휴 노드가 필요하다. 모든 노드가 사용 중이거나 노드의 용량이 부족한 경우 파드는 Pending 상태에 머물 수 있다. 따라서 노드 상태를 확인하고, 노드에 충분한 리소스가 있는지 확인해야 한다.
-
Scheduler : 쿠버네티스 스케줄러는 파드를 실행할 적합한 노드를 선택한다. 파드가 Pending 상태에 머무르는 경우 스케줄러의 문제가 발생할 수 있다. 스케줄러 로그와 이벤트를 확인하여 파드가 스케줄링되지 못하는 이유를 찾아야 한다.
-
Container Image : 파드가 사용하는 컨테이너 이미지가 존재하지 않거나 다운로드할 수 없는 경우에도 파드는 Pending 상태에 머무를 수 있다. 컨테이너 이미지의 이름, 버전 및 레지스트리에 액세스할 수 있는지 확인해야 한다.
-
Storage : 파드가 볼륨을 사용하는 경우 해당 볼륨을 사용할 수 없는 상태라면 Pending 상태에 머무를 수 있다. 스토리지 클래스, 퍼시스턴트 볼륨, 퍼시스턴트 볼륨 클레임과 같은 스토리지 관련 리소스의 상태를 확인해야 한다.
- Networking : 파드가 특정 포트를 사용하거나 다른 파드 또는 서비스와 통신해야 하는 경우, 네트워킹 구성에 문제가 있을 수 있다. 파드가 올바른 네트워크 정책을 가지고 있는지, 네트워크 연결이 가능한지 확인해야 한다.
파드가 Running 상태에 있지만 제대로 작동하지 않는 경우에는 다음과 같은 차이가 있다.
-
Running 상태 : 파드가 스케줄링되어 노드에서 실행 중인 상태이다. 파드는 기본적으로 Running 상태로 시작되며, 일반적으로 정상적으로 작동해야 한다. 하지만 파드 내부의 컨테이너 또는 응용 프로그램에 문제가 있는 경우에는 Running 상태이지만 잘 작동하지 않을 수 있다.
-
Pending 상태 : 파드가 스케줄링되지 못하여 실행되지 못하는 상태이다. Pending 상태에서는 파드 내의 컨테이너가 시작되지 않기 때문에 잘 작동하지 않는다. 파드가 Pending 상태에 머물러 있는 경우에는 스케줄링, 이미지, 스토리지 또는 네트워킹과 같은 이유로 실행이 차단되고 있을 가능성이 높다.
따라서 Pending 상태의 파드는 실행되지 못한 상태이며, 그 원인을 찾아 해결해야 한다. Running 상태의 파드는 실행 중이지만, 작동하지 않는 경우에는 파드 내의 컨테이너 또는 응용 프로그램의 문제를 해결해야 한다.